Рано или поздно перед любым программистом возникает задача - организовать работу какого-нибудь сервиса в режиме 24x7, т.е. он должен работать всегда. Потеря хотя бы одного запроса неприемлема и равноценна падению всей системы. Как решить "малой кровью" такую, казалось бы, сложную задачу?
Описанное далее решение не просто так является "бюджетным", оно не подходит для сервисов и систем реального времени, большие интервалы перед ответом являются нормой. Ниже рассмотрено функционирование подобной системы.
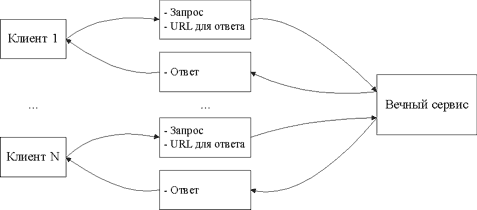
Как видно из рисунка, клиент отправляет запрос сервису с двумя параметрами - данными для обработки и адресом для обратного вызова. Через некоторое время T, когда данные будут обработаны, сервис присылает ответ на переданный ранее URL. Особенность рассматриваемой архитектуры в том, что величина T не критична для клиента и может достигать нескольких часов, основным требованием является то, что на любой отправленный запрос всегда придёт ответ.
Как можно объяснить допустимость такой задержки в работе сервиса? Специфичностью работы самой системы. Допустим, данные, переданные клиентами, будут обрабатываться людьми, а затем отправляться обратно. Это применимо к:
- системам документооборота (подача различных заявлений, их централизованная проверка и подтверждение или отклонение);
- системам проверки размещаемых данных (когда модераторы централизованно проверяют опубликованные сообщения, фотографии, видеоролики);
- любым системам обработки данных, для которых нет жёсткого ограничения по времени взаимодействия.
Так как система не может быть запущена один раз и работать вечно, она должна предусматривать возможность обновления кода и изменения структуры базы данных и при этом продолжать работать.
Минимальная комплектация для реализации такой системы:
- один балансировщик нагрузки;
- два сервера с запущенным приложением;
- сервер базы данных;
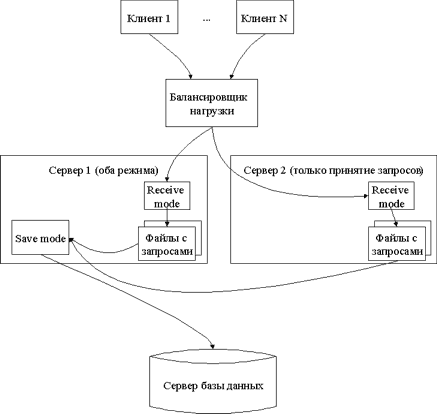
К задачам балансировщика нагрузки относятся следующие: принимать входящие запросы от клиентов и распределять их между функционирующими в данный момент серверами.
Рассмотрим, что происходит после того, как запрос доставлен на конкретный сервер
У запущенного приложения есть два независимых режима работы для получения запросов:
- Режим принятия запросов - каждый принятый запрос записывается в файл (назовём его receive mode);
- Режим обработки запросов - приложение обрабатывает файлы с запросами, а именно конвертирует их и записывает в базу данных (сохраняет запрос и url для ответа) (назовём его save mode).
Любой сервер может обрабатывать как свои запросы, так и файлы на соседних компьютерах, это позволяет запускать на некоторых машинах только режим "принятия запросов", а на более мощных серверах оба режима. Рассмотрим пример для системы с двумя серверами, один из которых более мощный.
После того, как данные попали в базу данных, они готовы для обработки, этим занимается отдельная система, возможно при участии человека. Для нас важно только то, что происходит, когда данные переходят в состояние готовых к отправке:
- Приложение берёт из базы данных информацию и url для отправки клиенту;
- Делает запрос на сервер клиента и передаёт данные;
- Если клиент не подтвердил то, что принял данные, они записываются в файл, как неудачно отправленное уведомление. Эти файлы, аналогично файлам с запросами, будут обрабатываться всеми серверами сообща. Если клиент подтверждает принятие запроса, файл удаляется.
Теперь рассмотрим, как будет происходить процесс обновления кода приложения и структуры базы данных:
- Все серверы переводятся в режим receivemode. Это делается для того, чтобы прекратить обращения к базе данных, теперь запросы будут только записываться в файлы.
- Программно отключается первый сервер - теперь балансировщик нагрузки будет посылать все запросы на остальные серверы, в обход отключенного.
- На выключенный сервер устанавливается обновлённая версия приложения.
- Обновлённый сервер включается в режиме receive mode и снова начинает принимать запросы и сохранять их в файлы.
- Аналогичным образом обновляются все серверы.
- Затем обновляется структура базы данных.
- После этого на серверах, которые работали в обоих режимах, включается save mode и возобновляется обработка сохранённых запросов и запись их в базу данных.
Из описания выше видно, что каждый посланный клиентом запрос записывается и обрабатывается в любой момент времени, даже во время обновления кода приложения и изменения структуры базы данных, т.е. соответствует требованию 24x7.
Плюсы рассмотренной архитектуры:
- работа в режиме 24х7 без потерь входящих запросов;
- возможность свободно обновлять код приложения и менять структуру базы данных;
- простое масштабирование системы;
- возможность переноса всей системы на другие серверы без потерь запросов.
Минусы рассматриваемой архитектуры:
- возможность наличия больших временных задержек между принятием запроса и отправкой ответа;
- жёсткая привязка к формату хранения запроса в файле. Поэтому структуру файла необходимо заранее хорошо продумать и не вдаваться в детали запроса на данном уровне (например, использовать поля, точно определяющие клиента, поле с данными запроса и url для обратного вызова);
- узким местом может стать большое количество маленьких файлов, об этом тоже лучше задуматься заранее (например, писать несколько запросов в один файл).
В целом, данное решение может подойти как мелким проектам, так и крупным масштабируемым системам, основной недостаток - временные задержки.
Никита МАНЬКО



















Комментарии